AI Worker 上岗记(中):星尘浩宇如何让 AI Worker 读懂金融审核里的“一堆纸”
发布时间: 2026-06-23
第一篇讲过:AI Worker 已经进入真实金融审核岗位,并在海外银行真实生产流程中接受连续运行数据的验证。第二篇要回答的是:这件事为什么难,以及星尘浩宇是怎么把一堆阿语、英语、扫描件、表格和手写资料,变成银行可以使用、可以审核、可以追溯的生产数据。
这个故事,是从一堆纸开始的
星尘浩宇面对的第一个现实问题,是一堆并不“标准”的纸。案例中的海外金融机构有一个非常现实的问题:大量业务仍然依赖纸质申请资料。信用卡申请、个人贷款申请、汽车融资租赁申请,每一笔业务背后都有申请表、身份证件、银行流水、工资证明、雇主证明、地址证明、授权文件、资产材料,以及大量扫描件和手机拍照件。
这些材料不是干净的结构化数据。它们可能是阿语,也可能是英语,也可能是阿英混排;可能从右向左排版,也可能有表格嵌套、印章遮挡、手写痕迹、扫描变形、低分辨率图片和缺页问题。对人来说,这些资料只是麻烦;对系统来说,这些资料是混乱、模糊、不可计算的输入。
在该银行的原始业务状态中,金融业务处理高度依赖人工。大量员工需要阅读纸质材料、识别字段、录入系统、核对信息、判断异常,再把结果交给后续审批流程。银行曾经引入 RPA,希望通过流程自动化提升效率。但在金融审核场景中,大量资料仍以纸质或非结构化文档形式存在。一旦 OCR 识别出现误差、字段抽取不稳定、材料类型无法准确判断,或跨文档信息无法自动核验,自动化流程就需要频繁转入人工处理。受限于上游数据质量和规则系统能力,许多传统 OCR+RPA 项目的自动化率长期难以突破 10%-15%。
这就是很多企业 AI 化的真实起点:真正把大模型用到企业业务里,第一步往往不是让它做复杂推理,而是先解决一个更基础的工程问题:这些“纸”能不能被系统稳定读懂。

真正的敲门砖,是小语种文档智能
星尘浩宇拿下这个银行项目,起点很具体:阿语文档智能。银行最先要解决的不是智能体概念,而是大量阿语纸质资料如何被准确识别、结构化和进入审核流程。
早期,星尘浩宇曾经服务过某海外国家级大型基础设施和工程类项目。那些项目里有大量纸质文档、工程图纸、阿语资料和英阿双语材料,需要进行电子化、结构化和归档。
当时市场上很多 OCR 产品在中文、英文场景下已经可用,但一到阿语和英阿混排场景,效果急剧下降。
原因很简单:阿语不是“换一种文字”的问题。
阿语从右向左书写,字母存在连写形态,版式复杂,阿英混排又经常出现在同一份材料里。真正麻烦的是数字:阿语里的 0 写作 ٠,像英文句号 “.”;阿语里的 5 写作 ٥,又像英文数字 0。
这类差异看起来只是一个小点、一个小圈,但落到车牌、表格、证件号、金额和日期这些高敏感字段里,一个数字识别错,后面的字段校验、规则判断和审批建议都会被带偏。
更关键的是,OCR 模型在公开样本里识别得准,不代表到了企业现场就能用。
企业资料里有大量私有化表单、历史扫描件、低质量拍照件、业务人员手写痕迹、印章遮挡、表格变形、字段缺失和不规则版式。公开测试集考的是“能不能识别一段文字”,企业生产环境考的是“能不能把一堆混乱资料变成业务系统可以使用的可信数据”。
所以,星尘浩宇当时面对的挑战有两层:第一层,是阿语和英阿混排本身带来的小语种识别难题;第二层,是如何在企业真实工程环境里,把 OCR 从“看起来准确”提升到“业务上可用”。前者考验模型能力,后者考验数据治理、场景训练、版式适配、字段结构化、质量评测和难例回流。
为了提升阿语资料的开发和评测效率,研发团队甚至专门学习阿语数字和常见版式规则。早期项目阶段,工程师会通过阿语车牌等数字密集场景练习识别和校验能力,逐步建立对阿语数字、书写方向和视觉特征的直觉判断。只有先解决“人能看懂”的问题,团队才有能力持续优化“机器能看懂”的问题。
这不是简单调 Prompt 能解决的问题。
星尘浩宇在通用模型基础上,围绕阿语 OCR、版式理解、字段抽取和跨文档校验做了大量后训练和工程化改造,逐步形成了面向小语种复杂资料的文档智能能力。当银行内部进行技术评测时,星尘浩宇在阿语识别、复杂资料处理和字段结构化上的效果明显优于其他方案。
这才是项目真正的入口。不是抽象地讲一个 Agent 能做什么,而是先回答客户最具体的问题:你最难处理的那堆纸,我们能不能读懂。
但银行项目真正发生的变化,并不是把原有 OCR 能力简单搬过去,而是把“能读懂纸”升级为“能承担金融审核岗位”。OCR 只是第一步,AI Worker 还必须完成文档分类、字段抽取、语义归一、跨文档一致性校验、业务规则映射和审批证据生成。
换句话说,银行要的不是一个 OCR 工具,而是一个能把纸质资料变成可信审批数据的数字员工。
这就是从 OCR 能力到岗位级资料理解的转化。
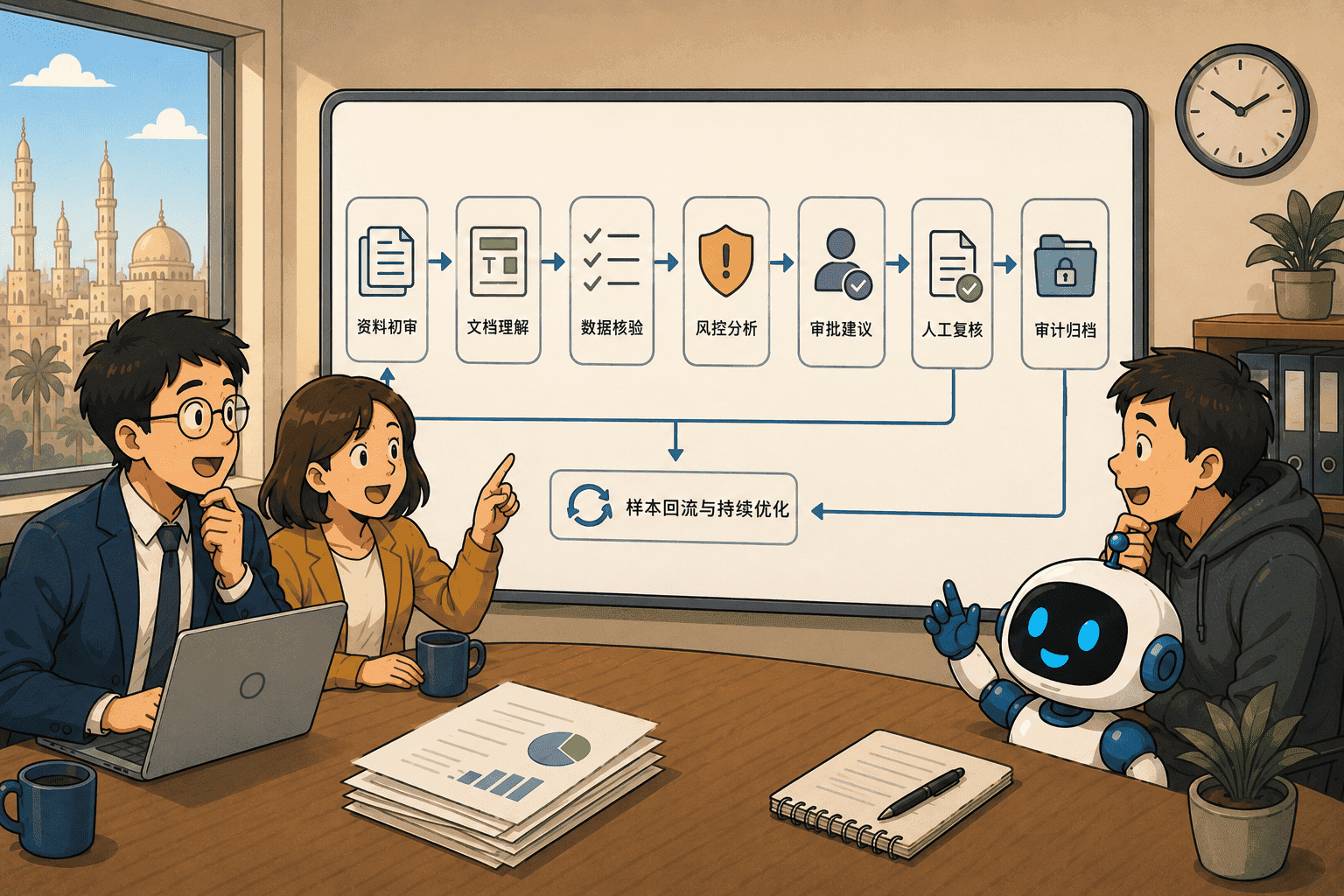
先切信用卡审核:AI Worker 必须从可验收岗位上岗
拿下文档识别和资料结构化能力之后,银行自然会提出下一个问题:既然 AI 能读懂资料,能不能让它负责更多审核工作?
这时,真正的产品判断开始了。很多企业做 AI 落地,容易一上来就把问题定义成“行业级 Agent”。但在真实生产环境里,行业概念越大,越需要先把岗位、权限、流程、指标和验收边界拆清楚。否则,AI 看起来覆盖面很广,却很难进入具体岗位,也很难被业务结果验收。
星尘浩宇的场景策略相反:先从一个足够具体、足够标准化、ROI 足够清楚的小场景打穿。小场景的价值不在于概念大,而在于边界清楚、系统改造少、异常样本真实、验收指标明确,能够在客户现场沉淀流程细节、系统连接、数据闭环和工程经验。
最后在这个案例选中的试点,是信用卡纸质申请资料审核。这个场景有几个特点。
-
首先,流程稳定。资料进入、分类、识别、抽取、校验、审核、补件、复核、归档,每一步都可以被流程化。
-
其次,边界清楚。AI 替谁做事、接什么任务、调用哪些系统、读取哪些数据、哪些动作必须人工复核、结果由谁验收,都可以被明确界定。
-
再次,系统改造风险低。AI Worker 可以围绕现有审批系统、影像系统、规则系统和人工复核流程工作,在不大改客户原有系统的情况下接管一部分高频、重复、可量化的审核任务。这种最小改造策略,可以显著降低企业 AI 化的部署风险。
-
第四,指标可量化。处理时长、字段识别准确率、关键字段准确率、自动化率、人工复核率、任务通过率,都能被计算。
-
最后,ROI 直接。节省多少人、缩短多少时间、减少多少错误、降低多少单位任务成本,可以直接和银行的采购决策挂钩。
这也是 AI Worker 和泛行业智能体的关键差异。泛行业智能体卖的是概念覆盖,AI Worker 交付的是岗位结果。
因此,星尘浩宇选择的是先让 AI Worker 在一个明确岗位上上岗,再通过相邻场景复制,从信用卡审核扩展到个人贷款 / 融资审核、汽车融资租赁审核等金融场景。
一个金融审核 OPT,是怎样像小型团队一样运行的
一笔信用卡申请进入系统后,背后不是一个大模型直接“看一眼然后判断”。真实的金融审核 AI Worker,也不是一个 Agent 在单点执行,而是一个围绕“完成一笔金融资料审核”组织起来的完整 OPT。
OPT 解决的是一个问题:一个任务单元如何像一个小型团队一样独立运行,并对结果负责。
在这个金融审核场景里,OPT 的目标很清楚:接收一笔申请资料,完成资料分类、字段抽取、跨文档核验、风险识别、审批建议和审计归档,并在必要时触发人工复核。它既要处理材料,也要跑流程;既要输出结论,也要留下证据;既要追求效率,也要满足金融场景的准确性、可解释性和合规要求。
所以,一个金融审核 OPT 内部,不是一个 Agent 在单干,而是一套由数字 AI Worker 承担高频处理、碳基 AI Worker 负责复核兜底,并由 Subagent、Skill 和 Tool 共同支撑的任务协同系统。
具体到一笔申请,流程大致是这样展开的。
资料初审子 Agent 接收任务,检查材料是否齐全,并判断文档类型。身份证件、申请表、工资证明、银行流水、地址证明、授权文件、资产材料,都要被分到正确类别。
文档理解子 Agent 进行 OCR、版式解析、表格理解、字段抽取和字段归一,把非结构化资料转化为统一的审批数据对象。
数据核验子 Agent 负责跨文档一致性校验。姓名、证件号、收入、雇主、地址、日期、银行流水和申请表之间是否一致,是否缺失,是否异常,都要被标记出来。
风控子 Agent 接入银行内部系统、征信、雇佣信息、资产核验、黑名单 / 灰名单、反洗钱名单等数据源,识别身份异常、收入异常、负债异常、材料造假、多头借贷和合规风险。
审批建议子 Agent 生成通过、拒绝、补件或人工复核建议,并输出可解释、可审计的审批报告。质量审计子 Agent 则在关键节点检查置信度、规则命中、异常样本和人工复核触发条件,并把失败样本、人工纠偏和审批结果回流到后续优化体系中。
到这里,一个金融审核 OPT 的数字任务流才算闭环:从资料进入,到资料理解;从字段结构化,到风险识别;从审批建议,到人工复核;从审计归档,到样本回流。
但这个 OPT 的目标,从来不是把金融审核做成“全无人化黑箱”。在金融强监管场景里,能不能无人化,不只取决于模型准确率,而取决于法律、政策、审计和责任归属。
因此,这个项目真正重构的不是“人有没有被 AI 完全替代”,而是“人应该站在流程的哪个位置”。
数字 AI Worker 接管高频、重复、规则清晰、可量化的资料处理和初步判断;碳基 AI Worker 则转向最终责任确认、异常判断和能力训练。
其中,碳基 AI Worker 的岗位被重新定义为“复审确认 + 数据回流”的协同角色。
数字 AI Worker 可以完成资料识别、字段抽取、交叉核验、风险提示和审批建议,但受金融监管、内部审批制度和责任归属要求约束,关键任务最终仍需要人类专家完成复审、签字确认和责任承担。
更重要的是,人工复审不再只是最后一道审核关口。人在复核过程中对识别错误、字段冲突、材料缺失、误判样本和补件争议所做的纠偏,会自动沉淀为标注数据,进入样本治理、评测集建设和 On-site Training 闭环,持续优化 Prompt、Skill、Workflow、Evaluator 和 Model。也就是说,人的每一次复审,既完成了业务审核,也在训练数字 AI Worker,让它越干越聪明。
这套 OPT 能够稳定运行,底层依靠的是 Tool / Skill / Subagent 三层结构。
Tool 是底层原子能力,比如 OCR 模型、版式解析器、征信接口、社保 / 雇佣接口、资产核验接口、规则引擎、审批系统 API。它解决的是 AI Worker 能不能连接真实系统、调用真实能力、执行真实动作。
Skill 是可复用业务能力包,比如文档分类 Skill、阿语 OCR Skill、字段抽取 Skill、跨文档一致性校验 Skill、反欺诈核验 Skill、风控规则匹配 Skill、审批报告生成 Skill。它解决的是如何把多个 Tool、Prompt、规则、Evaluator 和权限配置封装成稳定业务能力。
Subagent 是面向岗位职责的子智能体,比如资料初审子 Agent、文档理解子 Agent、数据核验子 Agent、风控子 Agent、审批建议子 Agent、质量审计子 Agent。它解决的是谁负责哪一段流程、拥有哪些权限、达到什么质量标准、什么时候交给人工复核。
因此,金融审核 AI Worker 不是一个孤立的 Agent,而是一个能持续运行的岗位型 OPT。它的外部表现是一名数字员工在承接审核任务,内部结构则是一套由 Tool、Skill、Subagent 与碳基复核岗位共同组成的可编排任务系统。
这套结构的好处是,每一层都可以单独迭代。换一个征信接口,只需要替换 Tool;新增一种资料审核逻辑,主要扩展 Skill;新增一个岗位流程,比如汽车融资租赁审核,则可以复用已有 Skill,组装新的 Subagent,并配置相应的人类复核与训练反馈机制。
它不是写死的项目脚本,而是一套可以持续复制、组合和进化的 AI Worker 资产。
快,不靠大模型硬推;准,也不靠大模型拍脑袋

金融审核场景对 AI 有一个非常朴素但严苛的要求:又快又准。
项目推进过程中,银行客户曾提出过一个明确目标:系统未来需要具备每日处理 20 万份文档的能力,以支撑业务增长和规模扩张。这意味着系统不仅要准确,还必须具备足够高的吞吐能力。
大量任务需要被快速处理,单笔任务也不能依赖一个昂贵的大模型逐页阅读、逐页推理、逐页生成。很多企业 Agent 的默认做法,是把任务交给更大的模型,认为模型越大效果越好。但在金融审核这种高吞吐场景里,这种思路很难兼顾效率、成本和稳定性。
在算力资源和模型能力都受约束的情况下,星尘浩宇没有选择用重模型硬推全流程,而是把金融审核拆成 OCR、抽取、校验、规则判断和审批建议等多个环节,按任务性质分别配置模型和规则策略。对比试验显示,分环节处理比端到端硬推更稳定,准确率也更高。高峰周接近 5 万笔任务,每个任务包含 13-17 张图片,这种拆解式架构既压榨了有限算力资源,也提升了系统在高并发场景下的速度、准确度和稳定性。
所以,这个项目里的关键技术动作,是把 OCR 从“识别文字”重构为金融审核 AI Worker 的“资料理解能力”。
银行审核场景要求系统不只识别图片里的文字,还要判断材料类型、定位关键字段、理解字段含义、完成跨文档一致性校验,并把可用信息转化为审批系统可以调用的可信数据对象。
因此,星尘浩宇没有把所有任务粗暴交给一个通用大模型,而是基于自研场景大模型,构建了“多模型架构 + 规则引擎 + HITL + 自进化”的分层协同架构:OCR、图像预处理、版式理解、字段抽取、文档分类等高频任务,优先由经过金融资料训练和工程优化的场景模型处理。
这套架构最终覆盖身份证件、银行流水、工资证明、雇主证明、地址证明、申请表、授权文件等多类金融材料,并适配扫描件、手机拍照件、PDF、图片及混合文件包等输入形态,同时能够处理阿语从右至左、阿英混排、表格嵌套、印章遮挡、手写痕迹和低质量图像等复杂情况。
系统快,是因为它知道什么时候不该用大模型;系统准,是因为每个字段、每条规则、每次调用和每个异常,都被工程化拆解、评测和治理。
从资料审核走向风险判断:AI Worker 必须对业务结果负责
如果只做到 OCR,价值仍然有限。
银行真正关心的不是“你能不能识别文字”,而是“这些资料能不能支撑审批判断”。比如客户申报的收入,是否和工资证明一致?工资证明是否和银行流水一致?雇主信息是否可信?负债是否完整披露?近期是否多头借贷?资产证明是否真实?是否命中黑名单、灰名单、反洗钱名单?资料是否可能被篡改?
因此,金融审核 AI Worker 里必须有风控子 Agent。
它的定位不是替代银行最终风控模型,也不是替代授信委员会,而是在资料识别和字段结构化之后,作为智能风控分析层和审批建议层,帮助银行把资料、外部验证结果、风控规则和历史审批经验组织起来。
这套风控能力分为三层:
-
数据可信层,负责文档识别、字段抽取、跨文档一致性校验;
-
风险识别层,负责反欺诈交叉验证、外部系统核验、银行规则比对;
-
决策建议层,负责风险摘要、风险等级、额度 / 利率 / 担保建议和人工复核建议。
更重要的是,它不是把审批完全交给大模型自由判断,而是采用“确定性规则 + LLM 解释推理 + 人工复核触发”的组合机制。
红线规则、准入规则、资料完整性规则、收入规则、负债规则、产品政策规则,由规则引擎处理;复杂材料理解、规则冲突解释、异常原因归纳、审批报告生成,由 LLM 处理;低置信度、高风险、规则冲突和关键节点,则触发人工复核。
这样做的结果是,银行既获得了 AI 的效率,又保留了金融系统最需要的可控性、可解释性和审计能力。
这才是金融审核 AI Worker 的关键跃迁:从资料理解、风险识别到审批建议的岗位级数字劳动力。
数据不出域,能力要进化:金融场景里的 On-site Training
金融场景还有一个更棘手的问题:数据敏感。
AI Worker 要越用越好,就需要数据回流、样本治理、模型迭代和评测闭环。但银行数据不能随便拿出生产环境,尤其是客户身份、收入、资产、征信和审批数据,更不能回到研发环境里自由训练。
这时,星尘浩宇采用了两套机制。
- 第一,合成数据后训练。
根据客户提供的基础资料、模板、字段和规则,团队生成了 10万+ 场景专项数据与评测样本,用于模型训练、规则校验和评测集构建。合成数据不是凭空造数据,而是围绕真实业务字段、真实文档版式、真实异常类型和真实审批流程进行场景化扩展。
- 第二,On-site Training 域内训练。
经过验证的模型和规则部署到客户生产环境,在客户环境内部完成训练、评测、灰度和回归。数据不出域,能力在域内进化。
这套机制让金融审核 AI Worker 形成了自学习、自进化闭环。
刚进入企业时,它像一个刚毕业的大学生,通过学习大量历史资料、表单、规则和案例,快速吸收岗位知识,实现“入职即上手”;上岗之后,它通过不断处理真实任务,吸收人工复核、失败样本、规则命中、审批结果和异常样本,迭代增量智力,实现“越干越聪明”。
这也是为什么一段时间之后,它的核心指标能够持续爬升,并最终超过人类专家基线的原因。
AI Worker 的壁垒不只是上线那一刻的模型效果,而是上线之后能不能持续进化。
不能进化的 Agent,只是自动化工具。能进化的 AI Worker,才是数字劳动力。

从攻克一个岗位,到沉淀一套可复制能力
如果只看结果,这像是一个金融审核自动化项目。但如果往里看一层,它其实回答了一个更大的问题:AI Worker 到底怎样才能从“演示系统”变成“真实岗位”。
答案不在于模型有多大,而在于能不能把文档、规则、流程、复核、审计和训练闭环组织起来,变成一套真正能上岗的岗位系统。
这也是这个金融审核案例最有价值的地方。
它不是一个孤立的项目交付,而是在真实金融生产环境里,把 AI Worker 从“能完成一个任务”,推进到“能承担一个岗位”。
当一名 AI Worker 能够在信用卡审核里稳定运行,背后真正沉淀下来的,不只是一套代码,也不只是一组模型,而是一批可复用的 Tool、Skill、Subagent、工作流、评测集、训练机制和人机协同方法。
下一篇,我们会继续回答第三个问题:当这套能力不再只服务一条审核流程,而是可以从信用卡审核扩展到个人贷款、汽车融资租赁和更多业务场景时,AI Worker 如何从一个金融岗位,走向规模化派遣。