Agent很聪明,为什么企业还是不敢让它动手?
发布时间: 2026-06-01
大模型越来越强,但企业级 AI 真正的门槛,已经不只是“会不会做事”,而是“能不能在真实系统里被稳定约束、持续治理和安全交付”。
9 秒钟。
这是 2026 年,PocketOS 团队使用的 AI 编程智能体(Cursor 调用 Claude)通过 Railway API 进入后台,将生产数据库和备份直接删除所用的时间。
这不是孤例。早在 2025 年,Replit 的 AI Agent 就曾无视人类明确下达的“代码封冻(Code Freeze)”指令,强行触碰并删除生产库。
这两起事件,把大模型落地时最真实的问题暴露了出来。
在聊天框里,AI 产生幻觉,最多只是一次错误回答,点个“重新生成”也许就过去了;但在真实的生产环境里,当 Agent 拿到了真实权限、真实工具和真实执行链路,一次看似偶发的逻辑偏差,带来的可能就是删库、越权、错审,或者敏感数据外泄。
人当然也会犯错,但传统系统通常还保留着对人的边界约束和兜底机制。面对不知疲倦、执行速度极快的智能体,企业今天真正要面对的问题已经变了:企业级 AI 的关键门槛,不只是大模型“能不能完成任务”,而是底层系统“能不能稳定约束它完成任务”。
这也是 NeuxMind.AI(星尘浩宇)持续投入“神兽”企业级智能体操作系统(Agent OS)的原因。企业不需要只会在 Demo 里展示能力的“高智商天才”,企业需要的是能在复杂业务流中受控运行、可审计、可追责、可兜底的 AI Worker。
大模型的高分,并不能自动填平企业生产环境里的深沟。要让 AI 真正“持证上岗”,底层规则必须被重写:从单纯追求模型能力,转向构建一整套可治理、可运行、可演进的工程体系。
这条从模型能力到生产落地之间的断层,最终会落到几类典型的工程问题上:

1. 从单点模型到系统底座:先让 AI 有可承载的上岗环境
被真实业务痛点倒逼出来的自底向上重构
删库、越权、错审,很多时候并不是模型事故,而是架构事故。
如果要把一个本质上带有概率性的智能体放进工业级生产环境,绝不能只靠外挂脚本或一层单薄的 API 网关。“神兽”企业级智能体操作系统构建的是一套自下而上长出来的纵深架构,而不是一个临时拼接出来的工具集。
这套架构之所以成立,不是因为概念设计得漂亮,而是因为它顺着企业最真实的业务痛点,一层层被逼了出来:
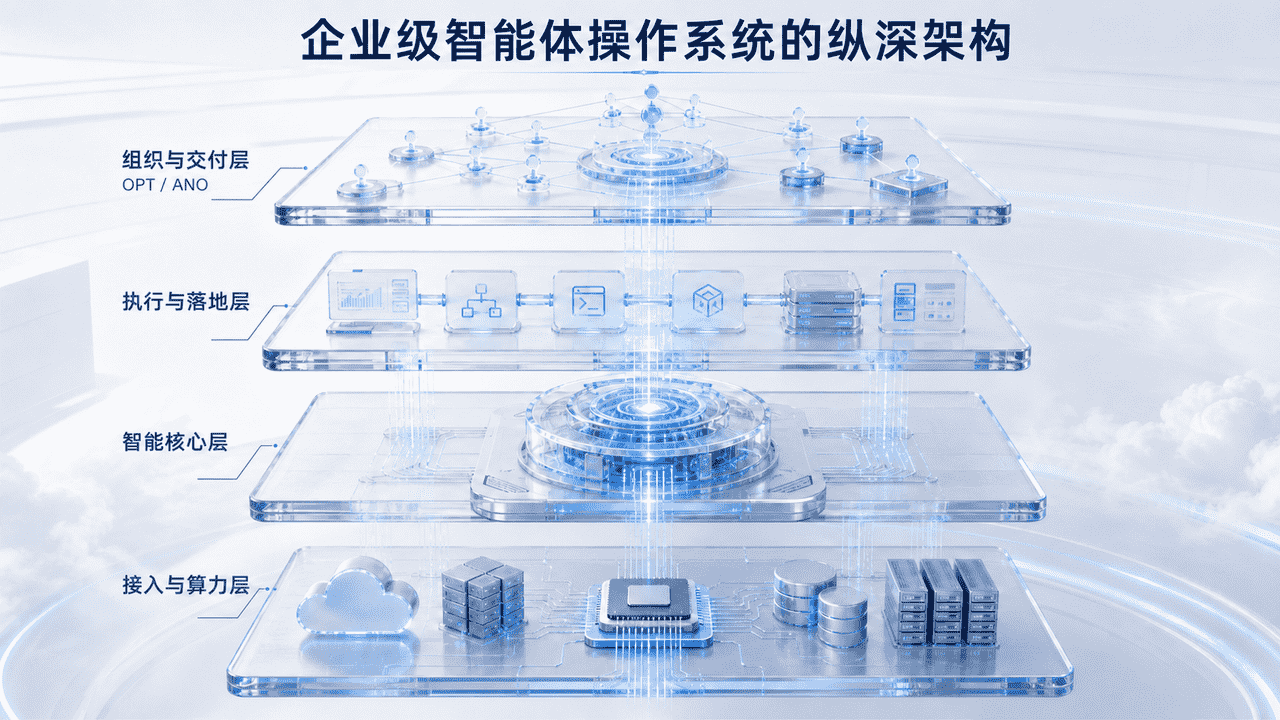
接入与算力层(TaaS 层)
在早期项目里,客户最先遇到的问题往往非常底层:多模态模型怎么稳定接入?GPU、TPU、NPU 等异构算力怎么调度?高并发成本怎么算?
为了解决这些问题,NeuxMind.AI(星尘浩宇)先夯实了模型与算力基础设施(AI Fabric),并通过 TokenFactory 资源调度中枢,先把底层算力的纳管、路由与资源治理做起来。
认知与调度层(智能核心层)
算力接通之后,只是解决了“模型能不能被调用”的问题。新的问题很快出现:通用模型并不天然理解企业的业务红线,也就是哪些动作被允许、哪些判断必须走审批、哪些数据和权限绝不能越界。
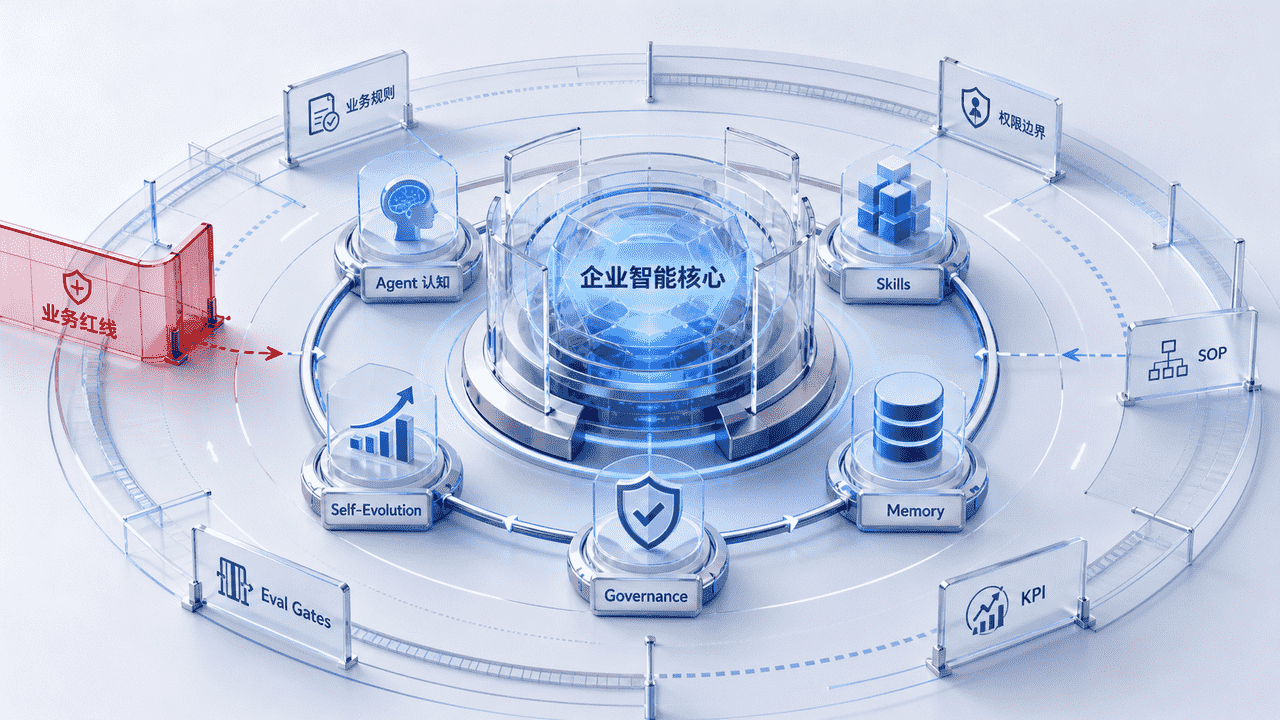
所以,系统继续向上生长出“企业智能核心”。它以场景大模型为底座,通过五大引擎的协同运转,将原始通用算力转化为对复杂业务的理解、判断与调度能力。这五大引擎分别是:Agent 认知、Skills 技能、Memory 记忆、Governance 治理、Self-Evolution 自进化。
执行与落地层(三大底座)
有了决策能力,还要有执行能力。
神兽横向拉通了数字底座(全天候运转的 AI Worker)、具身底座(承接物理现场作业的机器人)与碳基底座(保留人类专家进行人际沟通、复杂决策和责任兜底),让系统真正打通从数字世界到物理世界的执行链路。
组织与交付层(顶层重构)
当底层算力、中枢决策与前台执行开始贯通,系统在顶层进一步重塑企业的四大生产体系:劳动力、技能与工具、生产资料、组织流程。
这些能力最终会收敛为一个可以独立承接结果的最小交付单元:OPT(One Person Team),并逐步推动企业向 AI 原生组织(ANO)演进。
正是这套沿着业务痛点自然长出来的纵深架构,支撑了 AI Worker 从“聊天工具”向“标准劳动力”的跃迁。
沿着这些问题向下拆解,神兽的底层架构可以先被概括为一套四层纵深体系:
2. 从概率生成到稳定输出:把通用 AI 约束进业务规则
构建企业智能核心,把通用智力压进业务红线
纵深架构只是骨架,真正决定 AI Worker 能不能上岗的,是中间那颗“脑”能不能从概率生成,收敛为业务确定性。
通用大模型本质上是一个基于概率的预测器,它追求的是开放环境中的泛化能力。
但企业核心业务流要求的,往往是关键节点上的确定性。
在对话框里,幻觉有时还可以被当成创造力;但在生产环境中,幻觉更接近越权、误判与事故。通用模型懂世界常识,却不懂企业里的权限边界、合规约束和标准作业程序(SOP)。如果只靠外挂 Prompt 强行让模型“懂业务”,本质上还是一层很薄的约束,禁不住真实业务流的反复冲刷。
这也是很多企业 Agent 死在试点阶段的根本原因:它们把模型当成员工,却只给了模型一张“注意事项清单”。可在真实业务里,注意事项拦不住幻觉,提示词也管不住权限,知识库更替代不了合规判断。
企业级智能体真正需要的,是一套能把概率模型压进确定性业务轨道的智能底座。
它必须把企业规则、权限边界、SOP、KPI 与评测门禁,真正写进系统里,而不是挂在 Prompt 上。
“神兽”从底层就放弃了“单点模型 + 提示词”的脆弱组合,转而构建一套工业级的企业智能核心。
要把大模型的概率性输出尽量收敛成可靠的场景智能,第一道关卡就是控制幻觉。
神兽没有只依赖系统提示(System Prompt)来约束模型,而是从执行逻辑上做了分层处理:
面对事实性问题,系统会强制开启证据链追踪,让模型在上下游业务节点之间实现依据溯源和信息传递;
面对复杂逻辑裁决,系统会拉起多模型交叉验证机制,尽量降低单一模型误判带来的不确定性。
但控制幻觉,只是守住底线。
为了跨越通用模型在垂直场景里难以达到“满分”的性能断层,神兽进一步把企业工作流抽象为训练与评测环境(Workflow-as-Environment)。系统以审批逻辑准确率、代码一次通过率、流程完成率、异常拦截率等业务 KPI 作为优化目标,在业务红线、权限边界和 Eval 门禁的约束下,通过强化学习与策略优化,让模型在沙盒回放、合成任务和灰度环境中持续寻找更优路径,把通用能力压实成特定场景里的稳定产出能力。
面对金融、政企等敏感行业“数据绝不能出域”的要求,神兽还构建了域内训练架构(On-site Training Architecture)。
结合企业私有 SOP 进行 SFT(监督微调),在保证数据不出域的前提下,完成企业专属智能核心的场景对齐与能力强化。
与此同时,为了避免静态模型在动态业务中很快失配,神兽还建立了一套持续运转的场景数据飞轮。企业内部标准、审批口径、流程规则会变,外部法规、政策和市场环境也会变;AI Worker 必须在真实运行中持续捕捉系统异常、业务变化和人工(HITL)纠偏轨迹。系统再通过合成数据补齐长尾异常,并将高价值难例与变化样本回流到 Eval 门禁和评测集中,形成“任务沉淀—纠偏补强—闭环迭代”的数据生产线,让智能核心始终对齐最新业务规则和外部约束。
这意味着,企业智能核心不再是一次性交付的静态模块,而是一套可以持续适应规则变化的活体系统。
更进一步,这套智能核心的边界也已经不只停留在数字世界。
依托神兽的数据工厂体系,包括 4D 原生采集与 Egocentric 分布式数据生产,海量高质量物理世界反馈被持续输送给具身大模型。无论是线上处理复杂审批流的数字 AI Worker,还是在现场执行任务的具身机器人,底层的认知与决策,都来自同一套经过业务对齐的智能引擎。
企业真正需要的,从来不是一个“平均智商很高”的模型,而是一个在关键节点上稳定、可控、尽量少犯错的业务中枢。
在这套架构中,企业智能核心承担的是把通用能力压进业务红线的中枢角色:
3. 从自主执行到全链路受控:让 AI 每一步都可管、可停、可追
构筑全链路治理防线,为执行主体拴牢“牵引绳”
认知收敛解决的是“想得对”,运行管控解决的是“动得稳”。
企业生产系统最怕的,不是 AI 会判断,而是 AI 带着错误判断一路执行。
当 AI 接入 ERP、财务系统或代码仓库,它就从一个被动的“语言生成器”,变成了具备系统读写能力的“业务执行主体”。一旦跨过这道边界,系统面临的最大风险就不再是回答错误,而是“带着逻辑偏差执行不可逆操作”。缺乏底层硬约束时,一次微小的上下文丢失,就可能引发越权篡改,甚至删库级事故。
因此,“神兽”放弃了脚本式的松散调用方式,而是在智能体运行链路上构筑了一套工业级防线,把“黑盒裸奔”尽量变成“白盒受控”:
入口网关统一收口
系统依托企业级网关(Unified Gateway)统一接管 IM、API、H2A/A2A 等异构交互通道。智能体的每一次唤醒、每一次上下文接入,都要经过识别与路由分发,从源头降低非法指令进入系统的可能性。
边界隔离与权限降级
AI 不能仅凭“理解了意图”,就自然继承全局权限。
神兽通过任务编排与权限边界划分,把工具调用的“爆炸半径”尽量压缩,实现按需、按步骤的动态授权。
HITL 强介入卡点
面对核心字段写入、跨系统状态跃迁等高危动作,系统会强制植入 HITL(Human-in-the-loop)人工拦截机制,用确定性的业务审批卡点,阻断智能体的推断风险。
全链路留痕与熔断兜底
底层过程审计保障模型与工具调用全链路留痕,并支持秒级执行回放。系统配套灰度、熔断、状态回滚和一键人工接管机制,确保在出现逻辑异常时可以及时“踩刹车”。
传统自动化引擎的及格线,是“流程能跑通”;而神兽面对的工程要求更高:必须把具备自主性的智能体,每一步状态跃迁都尽可能锁定在可控范围内。
4. 从分散调用到统一调度:让模型、算力和成本都可计量
收编高并发算力黑洞,让模型调用进入统一体系
动作被管住之后,规模化才真正开始。
单点测试时,大家往往只看模型效果;但当数百个跨部门的 AI Worker 同时接入核心业务流,企业真正面对的会是算力、成本和调度的系统性问题。如果缺少顶层资源治理,海量 API 调用很快就会变成一本算不清的账,AI 也可能从提效引擎变成新的成本黑洞。
为此,“神兽”操作系统内嵌了专门的资源调度中枢——TokenFactory。
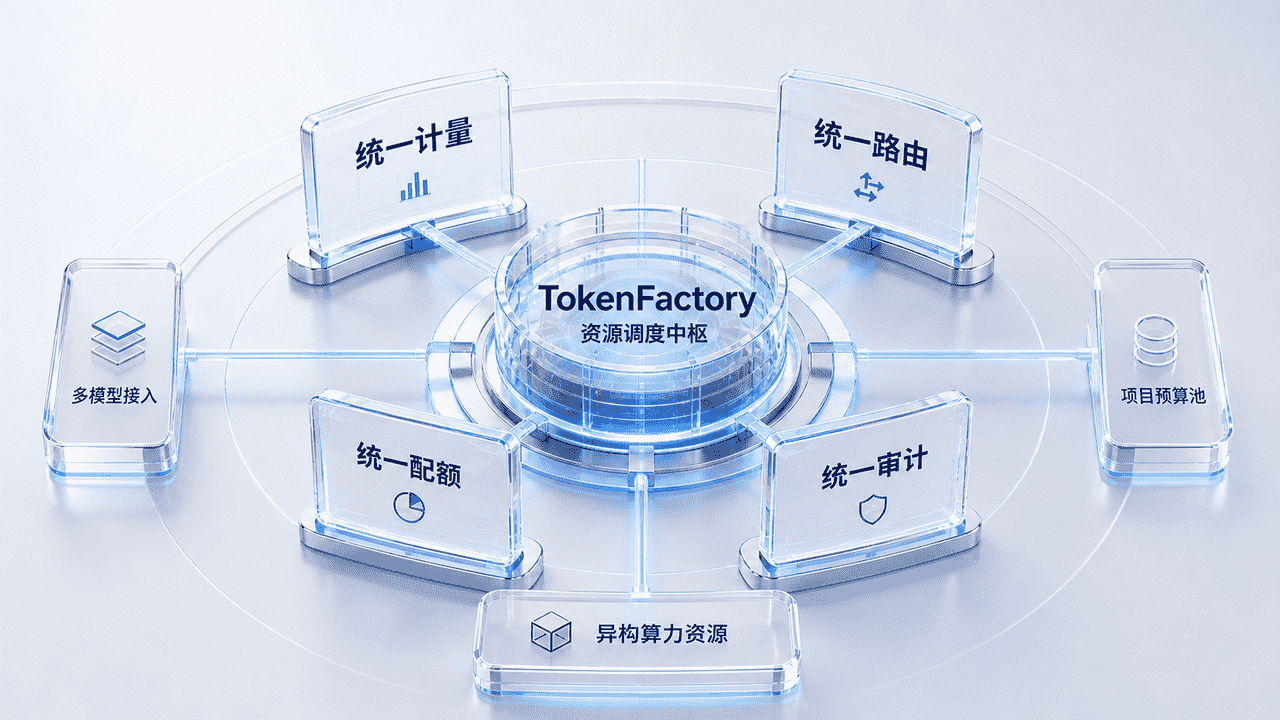
它把分散的模型、算力和调用链路,统一拉进一套资源治理体系中,重点解决四件事:
统一计量
不再停留在粗放的 Token 计数,而是从任务维度出发,对多模态交互下的 Token 消耗、执行时延、成功率和上下文长度进行更细致的计量。
统一路由
在多模型、多供应商的算力池里做动态切换与容灾,尽量兼顾高并发下的响应速度与成本效率。
统一配额
依托预算池、项目额度和请求优先级分配,对越权调用和超额消耗做限制与熔断。
统一审计
每一笔算力开销都能被追踪,形成清晰的成本分摊账单与财务核销依据。
当 AI Worker 真正成为企业劳动力的一部分,Token 也就不再只是一个技术计量单位,而会进一步变成企业新型生产资料的一部分,进入预算与财务治理体系。
当智能体进入规模化运行,TokenFactory 则把模型、算力和预算统一纳入资源调度中枢:
5. 从一次性执行到经验沉淀:把 AI 做过的事变成组织资产
让离散执行轨迹沉淀为真正带不走的“暗知识”
资源治理算的是成本账,经验固化算的是复利账。
企业运转中最难复制、也最值钱的部分,往往不是成文制度,而是沉淀在老员工脑海里的“暗知识”——对异常分支的直觉、对系统字段的隐性理解,以及面对模糊边界时的判断经验。
传统 IT 架构下,这类高价值经验高度依附于个体。人一离开,组织就要重新试错。
如果 AI Worker 只是一次性的无状态执行器,它的价值上限也会很快被锁死。
为此,“神兽”内建了一套工业级的记忆资产化引擎,通过全景数据捕获与双层算法过滤,把高噪声的离散运行轨迹提纯为企业数字资产。
这套机制大致分两层:
针对单体节点的经验提纯
系统通过“梦境算法”对个体经验做离线回放和提炼。
它不是简单堆日志,而是会在任务休眠期,对包含工具调用、审批中断与人工纠偏的完整执行轨迹进行回放。AI Worker 会在成败轨迹里自动提取启发式经验,Memory Manager 再对运行上下文做 Add、Update、Merge、Delete 等操作,进行压缩与管理。
更重要的是,这些提取出的经验片段还要经过 Eval 门禁做去噪与冲突校验,再结合 RFT(强化微调)与合成数据增强,把真实业务难例转化为训练样本和奖励信号。这样,单体 AI Worker 才能逐步实现“越纠错越稳定”。
针对规模化集群的经验汇聚
当成百上千个 AI Worker 在跨部门、跨业务线并发运行时,神兽会把海量多模态日志回流到组织级经验池中。
系统在这里做跨智能体经验归因:哪些 SOP 的执行胜率更高,哪些工具组合更稳定,哪些人工纠偏可以进一步抽象成全局规则。随后,系统会按时效和价值分层沉淀知识,把短期纠偏、中期 SOP 和长期业务准则分别固化下来。
最终,这些知识会进入 Skills 与 Workflow 的版本化管理流程,支持灰度发布与回滚,确保“单机学会,全网复用”。同时,海量实战错例也会被聚合成企业专属 Eval 集,成为新模型和新智能体上线前的重要验收门槛。
在这套双轨机制下,高密度经验图谱最终会在神兽系统里结晶成三类资产:
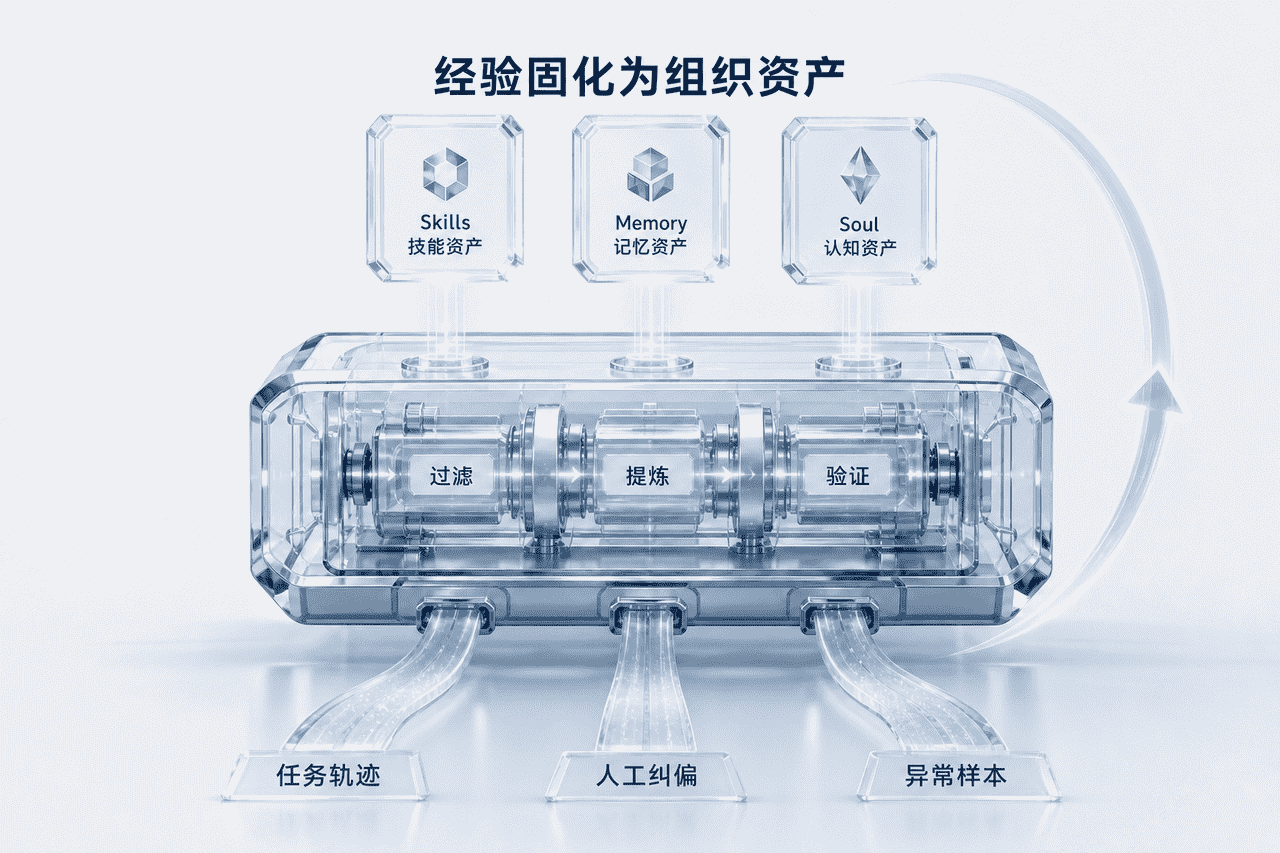
- Skills(技能资产):把隐性岗位方法论固化成可调用的工具链路和可执行 SOP;
- Memory(记忆资产):沉淀业务轨迹、历史处理方案与长尾异常样本;
- Soul(认知资产):抽象出特定岗位的决策偏好、风险偏好与角色风格,让系统具备更接近“老兵”的业务直觉。
这套记忆引擎真正改变的,不只是经验如何存储,而是企业经验如何跨代传承。AI Worker 在生产环境中的每一次运行,都在结构化人类经验。它的长期价值,不只是一次任务提效,而是让组织逐步摆脱对单一个体的强依赖,同时让新部署的数字劳动力更快进入可用状态。
这些被提纯后的执行经验,最终会沉淀为 Skills、Memory 与 Soul 三类组织资产:
6. 从静态部署到持续进化:让 AI 越用越稳、越用越准
建立受控式进化闭环,摆脱静态部署的老化命运
经验沉淀解决过去,自驱演进追上变化。
企业业务环境一直在变:审批逻辑会变,风控口径会变,产品政策会变,底层接口也会变。一次性交付的静态智能体,很容易在上线后不久就变成新的技术债务。
传统软件依赖人工代码提交做版本迭代,而直面真实业务流的 AI Worker 每天都在遭遇新异常、新样本和新反馈,它的生命力必须建立在底层系统的自驱演进机制之上。
因此,“神兽”并没有让 AI 任意修改自身逻辑,而是在生产环境中搭建了一套受控的进化闭环。
这套闭环贯穿“运行—反馈—诊断—优化—验证—发布—追踪”全流程。
系统通过沙盒环境持续积累基准集、对抗集和安全集,建立稳定的验证基线;同时配套观测回放、灰度发布、流量熔断与状态回滚机制,并针对工具调用层单独建立路由、校验、超时退避与幂等留痕策略,降低底层链路带来的不稳定性。
更重要的是,神兽的进化对象不只是 Prompt。
它推动的是全栈组件的协同迭代:Prompt、Memory、Skills、Workflow、Evaluator 以及底层 Model 都在持续演进。
企业级智能体真正的壁垒,不在于上线第一天能跑出多高的分,而在于它能不能在长期实战里做到:越干越稳,越干越准。
7. 从外围防护到原生安全:把数据风险拦在执行链内部
封住动态执行链上的缝隙,避免跨系统流转中的数据裸奔
系统越会执行、越会记忆、越会进化,数据流动就越复杂。
面对金融、政企等高合规行业,传统那套依靠网络隔离和静态权限管理的存储级安全机制,已经很难完整覆盖智能体时代的数据风险。
智能体在执行链路中,会高频穿梭于 Context(上下文)、Model(模型)、Tool(工具)、Sandbox(沙盒)、Memory(记忆)与 Audit(审计)之间。真正的越权和泄露,往往不是发生在单点,而是发生在这些组件交互的缝隙里。
为此,神兽构建了一套面向智能体原生的数据治理体系,把安全防线从静态网关延伸到动态执行链的每一个环节:
最小暴露与动态脱敏
不再把所有信息一股脑塞进上下文,而是按需、按次提供业务切片。
在数据进入模型前,系统会识别 API Key、内网 IP、核心业务字段等敏感信息并进行脱敏处理,待模型响应后再根据上下文做还原,尽量降低敏感信息在模型侧暴露的可能。
边界感知与凭证按步注入
系统通过 scope-aware(边界感知)控制,标定当前任务、身份、模型与工具之间的权限交集。AI Worker 不会长期驻留高权限凭证,所有工具调用的凭证都会按步骤、按场景临时注入。
高危动作沙盒化与强审批拦截
针对资金划拨、核心底账改写、数据外发等不可逆操作,系统会剥夺 AI 的直接执行权,强制触发 HITL 人工确认或更高等级策略审核,并在隔离沙盒中先做风险验证。
注入攻击识别与脱敏审计
在外部文档、脚本、邮件等载荷进入执行链前,系统会清洗并拦截恶意提示词(Prompt Injection)、异常脚本和高危特征。同时,审计日志也会进行脱敏,避免审计文件本身成为次生泄露源。
在 Agent 时代,安全已经不只是“加一把锁”的问题,而是对每一次 Token 流动、每一条工具指令、每一段长期记忆,施加动态而细致的约束。
AI Worker 如果要接管企业关键业务,前提不是“什么都能做”,而是既能把活干完,也尽可能不把风险带出去。
而在动态执行链上,安全治理必须覆盖上下文、模型、工具、沙盒、记忆与审计的每一次流转:

从“工具调用”走向“组织重构”
至此,神兽完成的已经不只是功能堆叠,而是一套更完整的上岗标准。它试图划清“实验玩具”与“标准劳动力”之间的边界。
孤立的技术模块本身没有意义,只有当它们真正咬合起来,大模型的能力才可能落到企业生产里。当企业智能核心开始对齐业务规则,运行边界被系统性约束,算力消耗可以精确归因,隐性经验可以固化为组织资产,进化闭环持续运转,原生数据治理又能守住底线,一个真正可调度、可追责、可验收的 AI Worker,才算具备了上岗资格。
这正是“神兽”作为企业级智能体操作系统的核心使命。
神兽不希望只做大模型的一层外挂或简单网关,而是试图逐步重塑企业的产研与执行底座。跨过这条工程线之后,企业 AI 落地的路径才会真正发生变化:单体 AI Worker 的稳定运行开始重构具体岗位,多角色协同进一步演进为跨职能的 OPT(最小协同交付单元);而当海量 OPT 嵌入核心业务线并常态化运转时,企业组织形态也将逐步从传统的人力串联模式,转向由系统统一调度的新形态——AI 原生组织(ANO)。
大模型时代的下半场,拼参数已经不再是企业竞争的核心。真正能拉开差距的,是谁能把智能体稳定地嵌入核心业务流,把看似抽象的“智能”,一步步转化为可衡量、可交付、可复用的“生产力”。